
De nombreux outils logiciels automatisés sur le marché aident à créer des backlinks sociaux ou web 2.0 vers une page/un site. Beaucoup de ces outils ont même l’option de faire du “spin”, mais les outils eux-mêmes fournissent très peu d’informations sur le fait de poster ou non un contenu identique.
Dans ce test, on distingue que le contenu dupliqué est le même contenu sur la même URL. Le même contenu sur deux ou plusieurs sites différents sera, pour nos besoins, appelé contenu syndiqué.
La publication d’un communiqué de presse est une forme de contenu syndiqué diffusé par les canaux d’information. La publication d’un communiqué de presse entraîne souvent la publication du même élément de contenu sur des centaines de sites. Néanmoins, vous constaterez que seules quelques-unes des instances publiées sont indexées. Il a été discuté dans de multiples forums que Google considère certains d’entre eux comme suffisants et que les autres sont exclus car ils n’offrent pas d’informations supplémentaires. Deux autres points essentiels sur les communiqués de presse :
Les communiqués de presse sont censés avoir le même contenu – et non pas être différents.
Les communiqués de presse sont classés dans la catégorie des nouvelles et sont diffusés par des sources d’information traditionnelles et le contenu apparaît sur des sites liés à l’actualité.
En supposant pour le moment que les communiqués de presse sont “Google Safe”, qu’en est-il de votre propre syndication en dehors des flux d’informations et sur les propriétés Web 2.0 ? La syndication Web 2.0 est un contenu qui est syndiqué manuellement ou automatiquement à l’aide de programmes tels que Syndwire, IFTTT ou Buffer, où le contenu est publié sur plusieurs sites Web 2.0 avec un lien vers une page Web cible contenant exactement le même contenu.
Pour ce test, 5 pages ont été créées avec des articles de 500 mots et une densité de mots clés inférieure à 1 %. Les pages ont été publiées en premier, puis nous avons déterminé celle qui se trouve au milieu. Toutes les pages ont été publiées et soumises à Google en même temps. Nous avons créé un article sur un blog WordPress exactement comme la page qui était classée n°2, pour lui donner l’espace nécessaire pour monter et descendre dans les résultats.
Nous avons fait passer le lien du Web 2.0 par Majestic pour nous assurer que le lien était exploré. WordPress.com Web 2.0 contenant le même contenu que la page de test et un lien vers la page de test. Le lien vers la page de test avait le style d’un lien traditionnel de source/citation au bas du contenu.

Au début, les pages ont été indexées et sont restées dans l’ordre de la capture d’écran. Une semaine plus tard, la page de test dont le contenu dupliqué web 2.0 pointait vers la page a perdu un emplacement, poussant les autres vers le bas. Il est intéressant de noter que la page n° 4 est passée à la première place. Nous ne savons pas pourquoi. Le numéro 5 est resté le même.
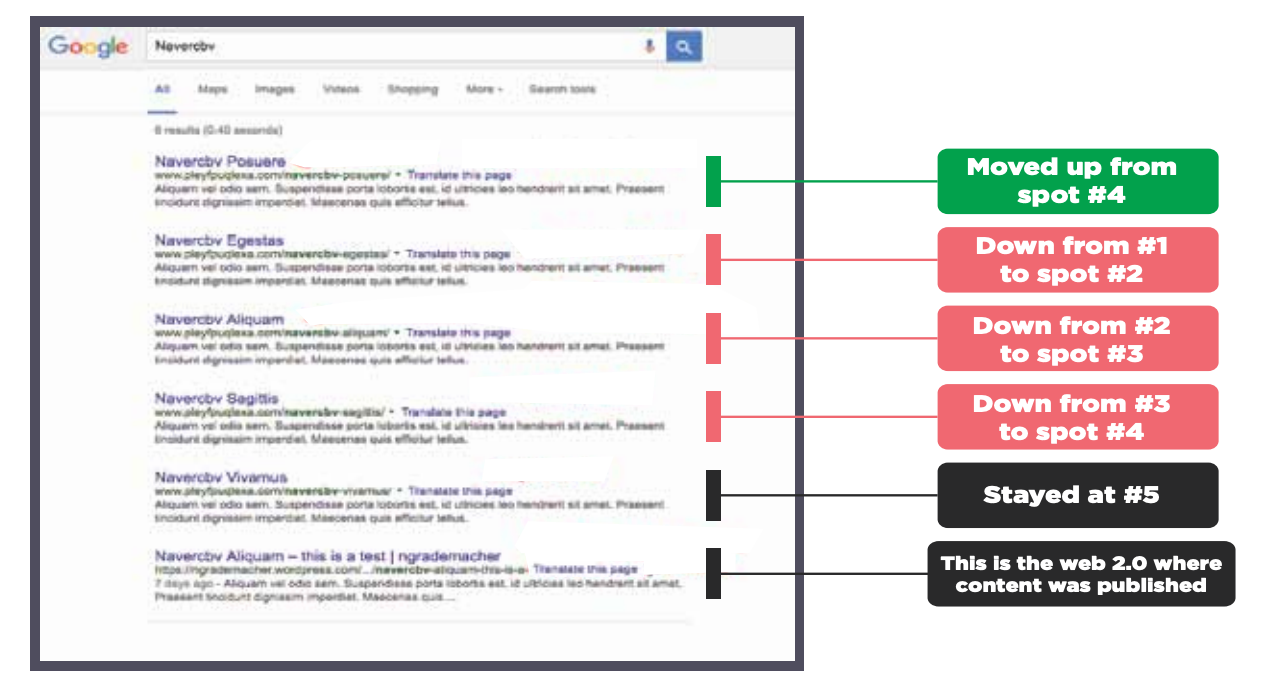
Il semble assez clair que l’établissement d’un lien entre un contenu identique et un autre contenu identique n’est pas une bonne idée. Une fois encore, nous avons indiqué que Google n’apprécie pas le contenu dupliqué/syndiqué lié qui est publié en dehors des canaux où un contenu identique est attendu.
Dans cette vidéo, Clint parle de ce test et de la syndication de contenu.
Test numéro 27 – Web 2.0 Duplicate Content.
Je veux faire deux choses. Tout d’abord, nous devons identifier le contenu dupliqué et ce qu’il représente. L’idée derrière le contenu dupliqué est d’avoir un article, une page web, et ensuite cette page web est publiée, ou cet article est publié sur un autre site web, et cet article est publié sur un autre site web, etc.
Maintenant, s’il s’agissait d’un communiqué de presse, ce serait de la syndication et personne ne dirait rien sur le contenu dupliqué, le contenu dupliqué vous nuit, vous ne devriez pas utiliser le même contenu partout. Mais les communiqués de presse, apparemment, sont exemptés de cela parce que vous ne dupliquez pas réellement le contenu, vous le syndiquez. Cela n’a aucun sens pour moi, parce que c’est exactement le même contenu, et c’est juste sur les sites de communiqués de presse par rapport à un site web.
Mais comme vous pouvez le voir, la forme naturelle du fonctionnement de Google, même dans Google Actualités, ils font le tri. Et généralement, plus les domaines font autorité ou sont fiables, plus le contenu sera classé haut que, disons, votre chaîne d’information standard. Ce contenu est syndiqué via une API.
Ensuite, vous avez le contenu dupliqué qui est sur votre page web ou votre site web. Et typiquement, vous allez voir cela principalement dans une entreprise locale, surtout si vous ciblez plusieurs villes. Et franchement, Google a compris cela. Ils savent que c’est attendu. Donc, si vous proposez des services de plomberie à Dallas, et que vous avez un ensemble de services que vous proposez, et que vous en parlez sur votre page plombier Dallas, et que vous proposez également tous ces mêmes services à Houston, l’algorithme a été formé pour être suffisamment intelligent pour savoir que vous n’allez pas réinventer la roue et écrire un contenu complètement unique pour votre page Houston, vous proposez exactement la même chose. Il y a tellement de choses et de façons de parler de la plomberie, n’est-ce pas ? On a compris.
Ce problème est lié à la syndication web 2.0, c’est-à-dire à la création de contenu dupliqué sur des sites web 2.0. La principale façon dont cela se produit est la suivante : vous faites la promotion de votre article et vous utilisez Syndwire, Onlywire, if this then that ou un de ces autres outils de création de liens, et vous avez configuré votre RSS pour qu’il affiche votre article complet. Dans la mesure où ce qui se passe lorsque vous le postez, votre article complet va dans votre flux RSS. Si ceci, alors, cela, ou quels que soient vos outils, prenez cet article complet, et ensuite postez-le sur votre Blogger, ou vous le postez sur votre WordPress, Tumblr, peu importe. Où qu’il soit posté, la copie exacte de cette page est mise sur cet autre site.
L’idée est en fait très bonne, vous construisez automatiquement des backlinks vers votre page. Le problème que nous voulons tester – ou si c’est un problème, d’accord, c’est un problème – c’est que vous copiez votre contenu exact et le mettez sur ces autres sites et est-ce que cela va vous nuire ?
Maintenant les résultats de ce test sont une semaine plus tard après la page de test web 2.0. Le contenu exact pointé vers le lien avec la page de la chauve-souris a perdu une place, poussant tous les autres vers le bas. Et le numéro 4 est passé au numéro 1 et le numéro 5 est resté le numéro 5. Donc, en termes de bla-bla, parce que c’est vraiment important à expliquer.
Lier un contenu identique à un contenu identique. Lier votre copie à l’original, n’est pas une bonne idée. Google n’aime pas ce genre de lien et cela crée du contenu syndiqué dupliqué dans les résultats de recherche. Vous pourriez finir par obtenir la désindexation de votre page parce que le site vers lequel vous l’avez syndiqué a plus d’autorité que votre site ou votre page Web.
Par exemple, si vous créez un site Google jumeau pour promouvoir vos produits et que vous copiez votre article sur le site Google. Il est plus que probable que le site Google surclasse votre page d’accueil ou votre contenu original en raison de l’autorité du site Google. Google aime Google. Google va promouvoir Google au détriment de votre contenu et dans la mesure où c’est la façon dont cela fonctionne généralement.
J’ai vu ça des tonnes de fois comme la méthode de syndication IFTTT fonctionne. Mais ça marche beaucoup mieux quand vous utilisez des extraits de vos articles, et que votre flux RSS publie les extraits et non le contenu dupliqué. De cette façon, cela fonctionne beaucoup mieux.
J’ai vu des gens qui se plaignent que la syndication IFTTT ne fonctionne pas. Et neuf fois sur dix, c’est toujours le fait qu’ils syndiquent l’intégralité du contenu et créent du contenu dupliqué. Et finalement, Google va filtrer quelque chose. Et généralement, ce sera le maillon faible. Et le plus souvent, c’est votre site web qui sera le maillon faible. Donc faites attention à ça.
Maintenant, nous allons refaire le test, parce que hey, on ne sait jamais, le gamin est revenu. Mais juste à partir de l’expérience récente, et des tests récents que nous avons publiés sur SIA. En particulier un aujourd’hui vous a montré comment Google filtre les résultats de recherche et cette méthode ici en est juste une autre. Ils ne choisissent pas votre contenu parce que c’était le premier publié dans le premier index et que vous avez le canonical, ils choisissent en fait sur la base de l’autorité.
Nous avons d’autres tests sur ce sujet, comme un test sur le fait de n’avoir qu’une description du contenu original. Consultez nos articles de test pour plus de détails.

Before you can receive free updates, link building strategies or SEO tips you need to confirm your email right now.
(It’s easy)
Just go to your inbox, open the confirmation email from the SIA, and click the link.

And that’s it!
PS: If you don’t see a confirmation email, please check your spam/junk or promotions folders. Sometimes the confirmation message ends up there by mistake.

Obtenez nos 7 études S.I.A. les plus controversées qui feront trembler la tête même les SEO les plus avancés d’incrédulité.
De plus, nous vous alerterons lorsque nous publierons de nouveaux tests au public.
Obtenga nuestros 7 estudios S.I.A. más controvertidos que harán que incluso el SEO más avanzado sacuda la cabeza con incredulidad.
Además, le avisaremos cuando publiquemos nuevas pruebas al público.
Get Our Most 7 Controversial S.I.A. Studies That Will Make Even the Most Advanced SEO Shake Their Head in Disbelief.
Plus we will alert you when we publish new tests to the public.
