Have you ever heard of robots.txt? If you're new to the world of SEO, you may not have.
While Robots.txt may appear to be a simple file it can have a big impact on your website's search engine ranking.
In this article, you'll learn what a robots.txt is, how it works, and why it's so important for your SEO strategy.

Here is what you will read in this article:
So, what exactly is robots.txt?
It's a plain text file that tells search engine robots which pages or sections of your website to either allow or block.
This is done by listing certain rules that the robots must follow when crawling your site.
By doing this, you can ensure that certain pages or sections of your site aren't accessible to search engines.
This can be helpful in a number of ways, such as preventing malicious bots from overloading your site or limiting access to certain pages that aren't meant to be indexed.
However, if not handled properly, robots.txt can also create problems for your site and hurt your SEO results.
That's why it's important to follow basic guidelines and best practices when creating and editing your robots.txt file.
In the next section, we'll go over some of these guidelines and offer a step-by-step guide to creating an effective robots.txt file that supports your SEO efforts.
Why is robots.txt important? Well, it's a crucial tool for controlling how search engine robots interact with your website.
By using this plain text file, you can block certain pages or sections of your site from being indexed, which can help prevent malicious bots from overloading your site.
However, if not handled properly, robots.txt can also create problems and hurt your SEO results.
To avoid such problems, it's recommended to follow basic guidelines and best practices when creating and editing your robots.txt file.
This way, you can guarantee that your site is supported and that certain pages are accessible or blocked as intended.
So, if you want to ensure that your site is in line with standard rules and supported SEO tools, obey the guidelines and use a recommended editor to create an effective robots.txt file that supports your SEO efforts.
One great feature of robots.txt is the ability to block non-public pages or sections of your site from being indexed.
This is crucial for preventing malicious bots from overloading your site and causing problems.
If you don't handle robots.txt properly, it can actually hurt your SEO results.
To avoid problems and ensure your site is in line with standard rules, it's important to follow basic guidelines and use recommended editors to create an effective robots.txt file.
By doing so, you can guarantee that certain pages are accessible or blocked as intended and support your SEO efforts.
If you want to improve your SEO results, it's important to Maximize Crawl Budget and handle your robots.txt file properly.
Blocking non-public pages or sections of your site can prevent malicious bots from causing problems and overloading your site.
If you don't follow basic guidelines, you may end up hurting your SEO efforts.
Don't ignore the rules!
Use recommended editors and follow standard solutions to create an effective robots.txt file.
By doing so, you can guarantee that certain pages are accessible or blocked as intended and support your SEO efforts.
Don't waste any more time on broken pages.
Preventing indexing of resources is a crucial step to ensure your website's success in search engine optimization.
You must obey the rules and use recommended editors to create an effective robots.txt file.
This file will allow you to block non-public pages or sections of your site, avoiding malicious bots that could cause problems and overload your site.
By blocking these pages, you can limit the crawl budget and support SEO.
By using a recommended editor and following the standard rules, you can effectively prevent indexing of certain pages or sections that may cause problems or overload your site.
This way, you can limit the crawl budget and avoid wasting resources.
It is important to obey the rules and use clear and concise language, avoiding repetition and complexity.
By doing so, you can guarantee effective results and support your website's SEO efforts.

Creating a robots.txt file is a crucial step in ensuring your website's success in search engine optimization.
To create a robots.txt file, you need to follow these steps:
1. Open a text editor
Use a plain text editor such as Notepad (Windows) or TextEdit (Mac) to create the robots.txt file.
2. Begin with the user-agent directive
The user-agent line specifies the search engine bots or crawlers to which the rules will apply.
For example, to apply the rules to all search engines, use the wildcard "*" symbol:
User-agent: *
3. Specify the directives
After the user-agent line, you can specify various directives to control search engine access to different parts of your website.
Here are some common directives:
Disallow: Use the "Disallow" directive to specify directories or files that you want to prevent search engines from accessing.
For example:
Disallow: /private/
Disallow: /hiddenpage.html
Allow: Use the "Allow" directive to override specific "Disallow" directives and allow access to certain directories or files that would otherwise be blocked. For example:
Allow: /public/
Sitemap: The "Sitemap" directive specifies the location of your XML sitemap, which helps search engines discover and index your website's pages.
For example:
Sitemap: https://www.example.com/sitemap.xml
4. Save the file
Once you have defined the directives, save the file with the name "robots.txt".
Ensure that the file is saved in plain text format without any file extension.
5. Upload the file to your website
Once the robots.txt file is created and saved, upload it to your website using an FTP client or the file manager provided by your web hosting service.
It's important to note that while the robots.txt file can help guide search engine crawlers, it's not a foolproof method to prevent all access to certain parts of your website.
Some well-behaved search engine bots may respect the directives, while others may not.
Remember, the robots.txt file is publicly accessible, so avoid including sensitive information in it.
By obeying the rules and using recommended editors, you can create an effective file that allows you to block non-public pages or sections of your site.
Note: It's a good practice to block engine crawlers from crawling your WP admin page and auto-generated tag pages to avoid duplicate content.
Plus, by blocking these pages, you can also limit your crawl budget and support your SEO efforts.

To ensure that search engines can access it easily.
It's important to follow these standard rules for Robots.txt and SEO to guarantee that your website is supported:
By following those rules, you can ensure that your robots.txt file is accessible and supported by search engines.
Now that you have created your robots.txt file, it’s time to place the file in the main directory of your site.
We recommend placing your file at:
https://yourwebsite.com/robots.txt
Note: robots.txt file is case sensitive. Make sure to use a lowercase in the filename.
When it comes to checking for errors and mistakes in your robots.txt file, there are a few key steps you should follow to ensure everything is in order.
As just discussed, make sure that your file is accessible and placed in the correct directory.
It's also important to avoid basic mistakes like using uppercase letters in the filename.
Next, use supported tools to test your file and ensure that it follows the standard rules and guidelines for robots.txt and SEO.
This will help you prevent common problems like blocking or limiting access to certain pages, or overloading your server with excessive requests.
Google has a free Robots Testing Tool to use.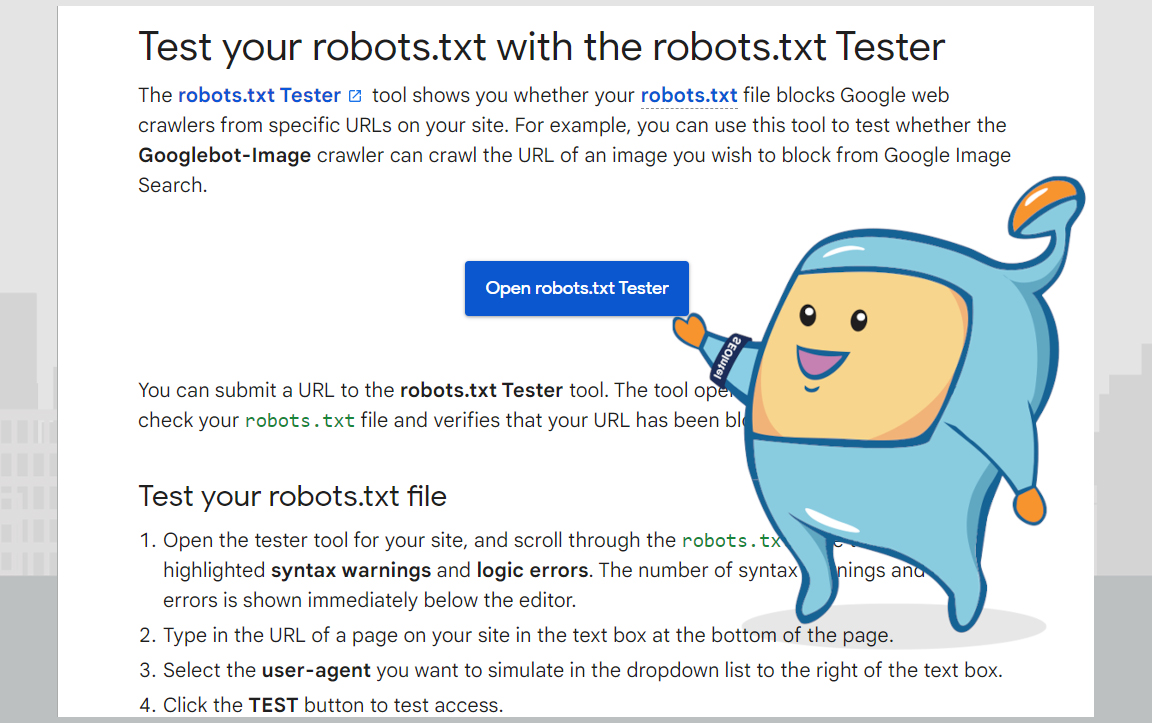
Finally, it's important to handle any problems or errors effectively, whether by editing the file directly or seeking out a recommended solution.
By following these steps and obeying the rules of robots.txt, you can guarantee that your website will be indexed properly and support your desired results.
In SEO, there are two ways to control which parts of your website are accessible to search engines: Robots.txt and Meta Directives.
While both tools serve a similar purpose, they operate in different ways.
Robots.txt and meta directives are both methods used in SEO to communicate with search engines about how to crawl and index website content.
However, there are some differences between the two.
Robots.txt is a text file located in the root directory of a website that specifies which pages or sections of a website should be excluded from search engine indexing.
It works by telling search engine bots which pages to avoid crawling.
The file contains instructions such as "User-agent: Googlebot" (specifying which search engine bot the directive applies to) and "Disallow: /private" (specifying the path to a directory or page that should not be crawled).
Robots.txt is a simple and effective way to block certain pages or sections from being indexed by search engines.
Meta directives, on the other hand, are HTML tags that are inserted into the head section of a web page.
They provide instructions to search engines about how to index and display the content on the page.
Some common meta directives include the meta title, meta description, and meta keywords tags.
These tags provide information about the content of the page and can help improve its visibility in search engine results pages (SERPs).
While robots.txt and meta directives both serve different purposes in SEO, they can complement each other when used together.
For example, if a website has a page that contains sensitive information that should not be indexed by search engines, the page can be excluded using the robots.txt file, and the meta robots tag can be added to further prevent indexing.
In summary, robots.txt is used to block search engine bots from accessing certain pages or directories, while meta directives provide information about the content of a web page to help search engines index and display it properly in SERPs.
In conclusion, robots.txt files play a crucial role in any successful SEO strategy.
They allow website owners to easily block certain pages or directories from search engine bots, ensuring that sensitive information remains private.
Learn more about robots.txt files by reading Google's helpful guide on how they interpret the robots.txt file.
With the right tools and knowledge, you can effectively handle any problem that may arise, ensuring that your website remains accessible and easy to navigate.

Get Our Most 7 Controversial S.I.A. Studies That Will Make Even the Most Advanced SEO Shake Their Head in Disbelief.
Plus we will alert you when we publish new tests to the public.
Obtenga nuestros 7 estudios S.I.A. más controvertidos que harán que incluso el SEO más avanzado sacuda la cabeza con incredulidad.
Además, le avisaremos cuando publiquemos nuevas pruebas al público.
Obtenez nos 7 études S.I.A. les plus controversées qui feront trembler la tête même les SEO les plus avancés d’incrédulité.
De plus, nous vous alerterons lorsque nous publierons de nouveaux tests au public.
Before you can receive free updates, link building strategies or SEO tips you need to confirm your email right now.
(It’s easy)
Just go to your inbox, open the confirmation email from the SIA, and click the link.

And that’s it!
PS: If you don’t see a confirmation email, please check your spam/junk or promotions folders. Sometimes the confirmation message ends up there by mistake.

