
There’s no doubt. Content in SEO is important. Is duplicate content an SEOs friend or foe? The SEO community is generally divided into two camps on the duplicate content issue: those that love it and those that hate it.
Personal feelings aside, we tested to see the amount of duplicate content that is acceptable. Some would say none, while others say duplicate content is the way to have a happy pocket full of money.
Attention: Do you have duplicate content on your site?
The duplicate content issue is a tricky subject for marketers. Some say it’s a shortcut to search engine optimization ranking, while others swear by its destruction.
We wanted to find out how much duplicated blocks of content could be tolerated before the search engines got mad and started penalizing us. So we ran some tests and found the answer!
Keep reading if you want to know what it is.

Duplicate content generally refers to substantive blocks of content that is duplicated on the same page of your website.
Sometimes duplicate content is intentional and sometimes it is accidental. Most of the time, marketers use non-malicious duplicate content. They intentionally create duplicate content to help their rankings.
This is perfectly acceptable to use, even on your money sites.
Before you learn about the different forms, let’s dispel the myths about how Google treats duplicate content.
Depending on who you follow, you may hear that duplicate content is the greatest thing since sliced bread. And that’s why you’ve landed here. You want to know the truth about duplicate content.
The idea of using duplicate content is great. It saves marketers both time and money in ranking. However, you may be wary of the dreaded duplicate content penalties.

When you do a search query in the search engines, how do you know what you are reading is unique?
These are the traditional signs:
The improvement of AI technology now eliminates many of the telltale signs of scraped articles.
Scraped or Syndicated content is not penalized when it adds value and the traffic to prove it.
Some of the most popular and well ranking sites use scraped content. They want the latest and greatest articles to serve their reader base. They accomplish this with scraped content.
Do you think big companies scour the net looking for someone that scraped or duplicated their content?
Most often, no. The majority aren’t worried about scraped content hurting their ranking.
Neither should you.
Google no longer ranks whole sites. Each page is judged on an individual basis. Duplicate content generally won’t hurt your whole site.
Many people use duplicate content for country-specific content or even local SEO. To this date, this is acceptable in Google’s eyes. As of right now, these versions of content that is duplicated is fine.
If you ever get a manual action penalty of your entire domain, clean up as much as you can and file a reconsideration request with Google.
If you have a penalty, the real issue is probably not duplicate content.
Not all types of duplicate content are created equal. There are eight types of duplicate content.
If it’s discovered the original owner of that same content can file a duplicate content complaint.
Since Google doesn’t want you to manipulate search results, it will give the original content priority and may remove your page from the SERPs.
While most website owners will never notice, there are some that watch for that.

Most people that are not purposely reusing content may find they inadvertently have duplicate content errors. These are generally technical in nature. It is a common issue that may cause traffic loss.
While they won’t cause a Google penalty, it is good to remove anything that can keep you from that first result. Or cause any “content bad” flags.
It’s important to have the right canonical set to your top-level domain. To do this you will want to set the canonical domain to your preferred url variation.
If your site is a non www but an HTTPs then your canonical link element should be https://yourdomain.com
But if your web server is configured wrong, your one page may also be showing as all of these to Google and other search engines:

Make sure you are correctly using 301 redirects to your preferred URL parameters.
Also set the canonical version as the preferred URL structure for each page to avoid common content duplication in Google.
An extra slight bonus is that it can increase your page’s authority so there will be no ambiguity. Using canonicals in SEO should be a part of all your standard content management systems.
If you have several pages that are similar, they may cannibalize each other. This means they could efficiently cancel each other out. Setting a canonical on each page will help.
Microsoft, Google and Yahoo! Are working together to accurately see unique pages. In 2020, Google says, “If your site contains multiple pages with largely identical content, there are a number of ways you can indicate your preferred URL to Google. (This is called “canonicalization”.)”
Simply add this tag to the head section of your pages.
<link rel=”canonical”href=”http://yoursite.com/dupicate-content-works”/>
This helps Google to know exactly which canonical url you want to rank.
Note: This is considered a hint for Google and other search engines, so the search engine ranking bots all have the option to ignore it.
Unless there are serious issues on your page, they will take it into consideration.
If you want to use a plugin. Here are two we recommend:

If content scraping is a concern to you, you can help stop people from stealing your content by adding the rel=canonical link to all your pages.
This helps tell the search engines that your content is the original.
It’s important to note that not all scrapers will grab all the HTML with the article so this may not work with all scrapers.
A homepage can still be accessed through different URLs without you knowing it. This is due to a misconfigured web server.
Aside from https://yourdomain.com, a homepage can be accessed through the following URLS:
When we look at these, they all signify the same page to us. But to a search bot, each of these is a unique page.
Choose one for your homepage. You’ll then implement a 301 redirect from the non-preferred version to the preferred one.
If the website is using any of the URLs for content, the pages should be canonicalized because redirecting them will break the pages.

Google Search Console is not only good for site performance and links, it is also good to see if you have to fix duplicate content issues.
Adding your site to Google Search Console can help you to see how Google sees your web pages on your site.
Once inside Google Search Console, go to Performance. Under the Search Results you will see any duplicate issues.
We stress the importance of internal linking for the content on your website. If your canonical is set to https://yourdomain.com/duplicate-conent-rules make sure that every internal link to that page uses that same URL in that exact way.
If you have the URL canonical set to https://yourdomain.com/internal-links/ make sure that all content on your website that will link to this is exact.
If you are buying links through services like Dori’s SEONitro, make sure your inbound links from high domain authority sites match your canonical.
Remember: You want all the domain authority from those sites to fully flow through to your site.
Dori goes to great lengths to make sure the link metrics will push the ranking needle. Using the correct link path will help you benefit from that link equity.

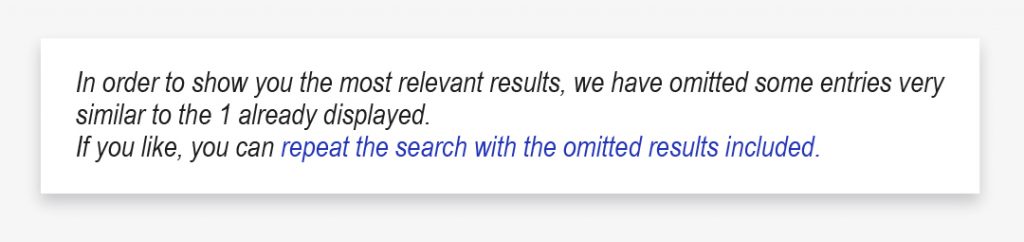
There is an easy way to find if Google sees your content as unique. Take a piece of content and paste that into the Google search bar. This is one of the most accurate duplicate content checkers.
If Google sees original content, you will see normal search engine results. However, if Google sees that content as duplicate, you will see the following result.
Here are three of the most popular tools for duplicate content checkers. These will help identify duplicate content easily:

Will duplicate content tank your site and hurt your SEO ranking? In the end, we could not get a negative factor. The target page had all this duplicate content and did not turn into a negative factor.
There is no duplicate content penalty. Google won’t penalize you with a duplicate content penalty.
Will duplicate content sandbox you? We did not get a sandbox. The sandbox is the idea that something that won’t rank for days or weeks.
How much duplicate content should you have? While we couldn’t get a penalty from duplicate content, we know that Google will filter the search results.
If you are getting filtered, you can fix duplicate content on your own site using the methods in this article.
We have found that as long as you have 51% unique content, is one way to help avoid the filter. As Google has different scores for different keywords, you may need a higher percentage of unique content to rank.

According to Google’s Guidelines, duplicate content on your website is not grounds for action on that site unless it appears that the intent of the duplicate content is to be deceptive and manipulate search engine results.
In 2015, John Mueller said, “No duplicate content penalty” but “We do have some things around duplicate content … that are penalty worthy”
Google knows that users want diverse and original articles to consume. Not the same article over and over. It doesn’t want readers to land on your site and see the same rehashed information found elsewhere.
Nothing to see here, move it along.
Google wants unique, relevant to the searcher’s query, and informative, original articles for readers. The quality score drops are going to get you if you use a lot of duplicate content.

It’s frustrating when you have pages that have disappeared from the search engines results. You’ve wasted money on crawl budgets. Traffic drops. And your SEO clients start calling. Duplicate content can be a big thorn in the side for many unaware SEO marketers.
While there’s some easy solutions to implement, know that the solution may vary depending on the situation.
Duplicating content makes life so much easier. Just make sure you have a page that is 51% unique and check the search engine ranking to see if it will be filtered.
Setting this up will inform Google what parameters are working, instead of waiting for them to figure things out.
This is used to consolidate the alternate version of a page (mobile or country/language pages). For the country /language page, hreflang is used to display the correct result.
According to John Mueller during the Webmaster Hangout, fixing the hreflang will not increase the ranking. However, it will help show the correct version. This is because the alternate versions have already been identified by Google and signals were consolidated for different pages.
This is particularly important in the fight against duplicate content. We’ve found that using a meta robots noindex tag is not effective enough.
Instead, we use the rel=canonical to designate each URL for your pages.
Make sure the keywords and pages you are going after aren’t going to be cannibalized.
URL parameters are important when it comes to duplicated content. URL parameters are often created dynamically. This leads to many pages being created with the same or similar content.
These url parameters show up in the search results and it is filtered out as similar results or viewed as low quality content.
If you find parameters that are purely duplicate and do not offer value independently from the original page, add a canonical. Make sure to point it to the original page.
This will prevent duplication issues with the pages by preventing the display of alternate versions.
We tested and can confirm there is no duplicate content penalty. You now know that Google handles duplicate content by filtering out the results in the SERPs.
Duplicate content issues happen. If you are struggling with technical duplicate content, it can be easily cleaned up. And now you know how to prevent it in the future.
Google doesn’t have an issue with duplicate content. It has more of an issue with low quality and bad user experience content. This will have a negative effect on your search results.
If you are using duplicate content, make sure you are using 51% unique content to be safe. Keep an eye on your quality scores.
When using duplicate content properly, you will see improved ROI for both time and money invested in your content management.

It takes a village to run a successful business. Several staff members contribute to the articles under this bio. You can read more about them here: full bio here.

Get Our Most 7 Controversial S.I.A. Studies That Will Make Even the Most Advanced SEO Shake Their Head in Disbelief.
Plus we will alert you when we publish new tests to the public.
Obtenga nuestros 7 estudios S.I.A. más controvertidos que harán que incluso el SEO más avanzado sacuda la cabeza con incredulidad.
Además, le avisaremos cuando publiquemos nuevas pruebas al público.
Obtenez nos 7 études S.I.A. les plus controversées qui feront trembler la tête même les SEO les plus avancés d’incrédulité.
De plus, nous vous alerterons lorsque nous publierons de nouveaux tests au public.
Before you can receive free updates, link building strategies or SEO tips you need to confirm your email right now.
(It’s easy)
Just go to your inbox, open the confirmation email from the SIA, and click the link.

And that’s it!
PS: If you don’t see a confirmation email, please check your spam/junk or promotions folders. Sometimes the confirmation message ends up there by mistake.
