
Have no idea what robots.txt is and what it does for your site? Do you really need to know what it is and how to use it? In this article, we talk about what robots.txt is and how to install robots.txt on WordPress, with or without a free plugin like Yoast SEO.
The first thing I should say is that by default, WordPress automatically creates a default robots.txt file for your site. So even if you don’t lift a finger, your site should already have the a WordPress robots.txt file.
But, if you knew that, you’re presumably here because you want to know more, or add more functionality (instructions) to this file.
To that end…
…Are you new to robots.txt, and feeling totally lost?
Maybe someone on your team designated you to take care of something on the robots.txt file, such as “Make sure such-and-such is added/blocked on robots.txt.”
Whatever the case, I’m going to pretend you know nothing about robots.txt, and quickly tell you everything you need to know to get started with this crucial text file.
Before we began, I should state this article covers most WordPress installations (which are at the root of a domain). In the rare case where you have WordPress installed on a subfolder or subdomain, then how and where you install robots.txt may differ from what I detail below. That said, these same principles and key ideas still apply.
You probably know that there are web crawlers that visit sites and possibly index the data found on those sites. These are also called robots. They are any type of bot that visits and crawls websites on the internet. The most common type of robot are search engine bots or search engine crawlers like those of Google, Bing, etc. They crawl pages and help search engines index the pages and rank them in the SERPs.
It’s said that, upon arriving at a site, one of the first files that search engine crawlers or web crawler are supposed to look for is the robots.txt file.
A robots.txt file is a simple text file that provides instructions for search engine crawlers and web crawlers. It was created in the mid 90s out of the desire to control how robots interact with pages. It allows web owners and web developers the ability to control how the robots can interact with a site. You can block robots from accessing particular areas on your site, show them where your sitemap can be accessed, or cause a delay on crawling your site.
So, in a way, if there are some sections of your site that you do not want to be crawled, a robots.txt file may instruct abiding user-agents to not visit those folders.
There are some crawlers that have been designed for mischievous purposes, and those crawlers may not abide by the standards set by the Robots Exclusion Protocol.
That said, if you do have sensitive information on a certain portion of your site, you may wish to take extra measures to restrict access to that data, such as installing a password system.
For most WordPress installations, the robots.txt file is on the root domain. That is, for most WordPress sites (which are installed on the root directory of a domain), the robots.txt file can be found at /robots.txt.
So, for example, this site (seointel.com) has a WordPress installation on the root of its domain. So, its robots.txt file can be found at /robots.txt (https://seointel.com/robots.txt)
If you don’t have a robots.txt file or if you just have the default file by WordPress, crawlers can crawl all pages of your website and they would not know which areas they should not crawl. This should be fine for those just starting with a blog or sites that do not have much content. However, for sites that have a lot of content and sites that handle private information, a robots.txt file would be needed.
For sites that have a lot of content, it would be good practice to set up a robots.txt file that sets which sites not to crawl. Why? This is because search engine bots usually have a crawl quota, crawl rate, or crawl budget for each website. The bots can only crawl a certain number of pages per crawl and if they do not finish crawling all your pages, they will resume crawling them in the next crawl sessions. This means that for large sites, crawling the site may be slower and cause slower indexing of new or updated content. This issue can be fixed by disallowing crawlers from crawling unimportant pages of your site such as the admin pages, plugin files, and themes folder.
By doing this, you can optimize your site and make sure that the robots only crawl important pages of your site and that new pages are crawled and indexed as fast as possible.
There are also instances when duplicate content cannot be avoided on a site. Some choose to add the page in the robots.txt so that the duplicated pages will not be crawled.
Another is when your site is seeing high bot traffic which can be impacting your server usage or server performance. You can block certain bots from crawling your site or you can set a crawl delay. This helps improve performance issues of your site.
Adding your sitemaps to your robot.txt file also helps Google bot in finding your sitemap and crawling the pages on your site though this is often not added anymore as the sitemaps can be set up in Google Search Console.
The robots.txt file has two main commands. The User-agent and disallow directive.
Aside from those two common commands, there are also the Allow command which speaks for itself and as a default, everything on your site is marked as Allow so it is not really necessary to use in. This can be used though when you Disallow access to parent folder but allow access to subfolders or a child folder.
There are also commands for Crawl-delay and Sitemap.
There are also instances when you do not want a page to be indexed and the best course of action may not be just disallowing in the robots txt file. The Disallow command is not the same as the noindex tag. While the disallow command blocks crawlers from crawling a site, it does not necessarily stops a page from indexing. If you want a page not to be indexed and to not show up in search results, the best course of action will be to use a noindex tag.
Perhaps the best example is your own example. Since you’re reading this, you probably have a WordPress site. Go to that site’s actual robots.txt file – add /robots.txt to your root domain. (If you don’t yet have a WordPress site, just follow the examples below.)
What do you see?
You may see a blank file or empty file, which isn’t the best, but there’s technically nothing wrong with that. It just means that crawlers can go where they can.
User-agent: *
Allow: /
So, the way robots.txt instructions work is that there’s a web crawler or user-agent callout (this can be for all user-agents or specifically-named ones), followed on the next line by a certain instruction (usually either to allow or disallow certain folders or files).
The asterisk (*) implies all, meaning all user-agents, and the slash (/) means the domain. So, these two lines of code are effectively saying, “All user-agents are allowed everywhere on this domain.”

Believe it or not, this one has exactly the same implications as a blank robots.txt file and is often the default robots.txt file.
Let’s look at a slightly more complicated one…
User-agent: *
Disallow: /wp-admin/
We know that the asterisk (*) means all bots/crawlers/user-agents.
The wp-admin folder is disallowed.
So, this is a callout (an instruction) prevents search engine crawlers and other bots from crawling and going through the wp-admin folder. (This is understandable, because the wp-admin folder is usually a secure, login-only area of a WordPress installation.)
If you have a paid-access area, download page, or private files that aren’t password-protected, that download page could be visited by someone using a Chrome browser, which I suspect would alert Googlebot, saying, “Hey, this person left their paid area wide open.”
Then, Googlebot might come and unknowingly index your paid area.
Now, the chances of someone finding your paid-access area via a Google search is low…unless maybe they have a knowledge of search engine operators and know what to look for.
User-agent: *
Disallow: /wp-admin/
User-agent: Exabot
Disallow: /
User-agent: NCBot
Disallow: /
We know from before that all bots are instructed not to go through the wp-admin folder. But we also have additional instructions for user-agent field – Exabot and user-agent NCBot.
This means that you restrict bot access to those 2 specific user-agents.
Notice that for Exabot and NCBot, even though the disallow instructions are identical, they’re still paired with either of the two.
And, notice that there’s a blank line after the instruction (disallow) for all user-agents, a blank line after the instruction (disallow) for Exabot, and presumably, a blank line after the instruction (disallow) for NCBot.
That’s because the rules for robots.txt specify that if you have an instruction for specific user-agents, then those user-agents must have their own callout (be specifically named), and on the next line(s), list the instruction(s) for that user-agent.
In other words, you can’t group specific user-agents or generally assign instructions to a group of specific user-agents. You can use the asterisk (*) to call out to all user-agents, but you otherwise can’t group specific user-agents without using the callout-next-line-instruction example above.
So, basically, there has to be a blank line after the last instruction for one (or all) user-agents followed by the callout of another user-agent (followed by an instruction on the next line).
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /wp-snapshots
Disallow: /trackback
So, all user-agents are disallowed from wp-admin, with the exception that they’re allowed to crawl a specific file in wp-admin (admin-ajax.php), and disallowed from any url that begins from the root with wp-snapshots or trackback.
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /wp-snapshots
Disallow: /trackback
Sitemap: https://example.org/sitemap.xml
Sitemap: https://example.org/sitemap.rss
This example is a continuation of the one used in the preceding example, with two added lines telling search bots (or web-crawlers) the file path for the RSS and XML sitemaps.
There’s a little bit more that can be done with robots.txt, but I think these examples are plenty enough for you to get started with.
So, as I mentioned earlier, your WP site may already have a robots.txt file that was added during installation (just check yoursite.com/robots.txt).
However, you may wish to customize it or give it some functionality. There are generally 2 ways to install (or edit) a robots.txt file on a WordPress installation–one using a plugin, and the other without the use of a plugin:
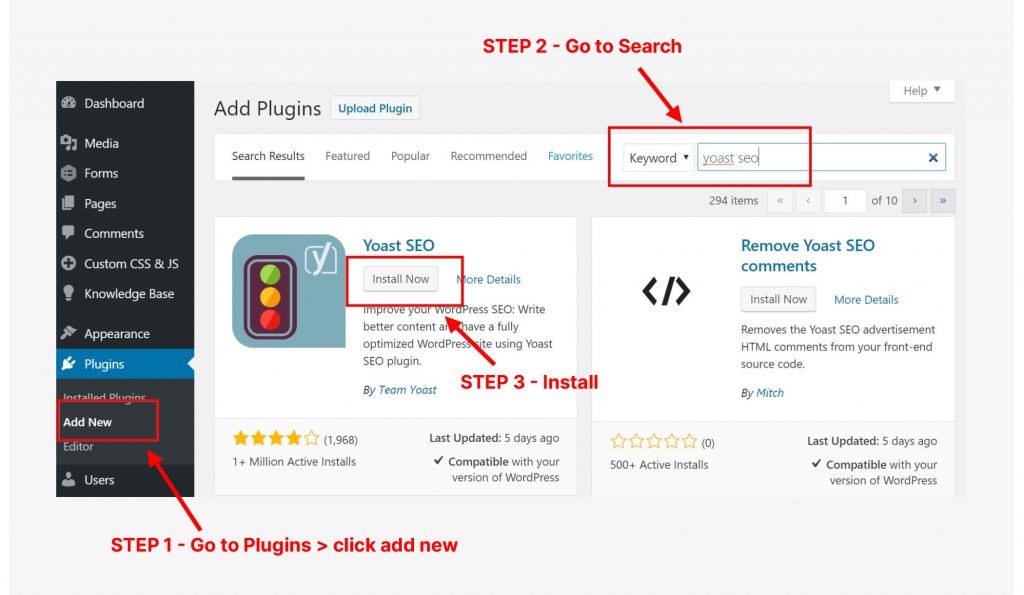
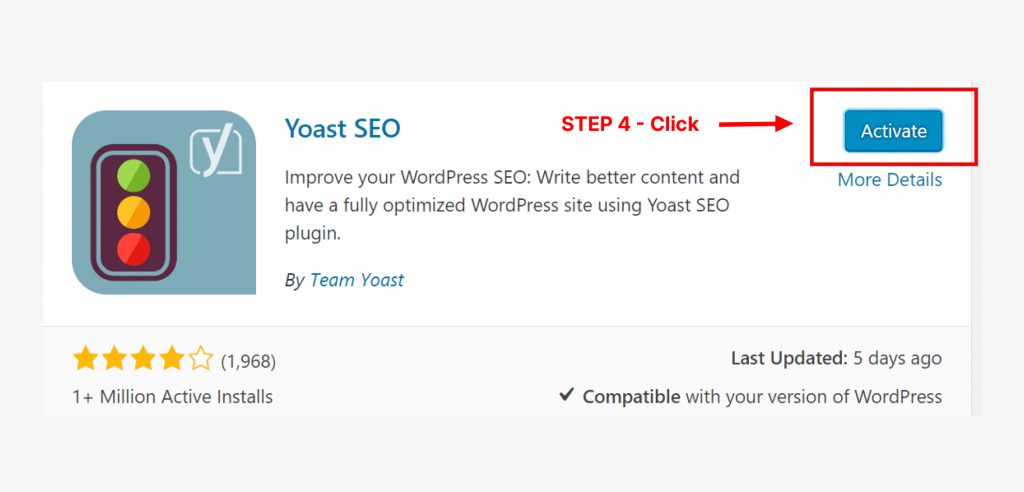
Now that you have Yoast SEO installed, here are the steps you can take to edit or install a robots.txt file. (Note: if Yoast has changed since the time I’m writing this, some of the steps below may be different, but I believe Yoast SEO will still have a robots.txt feature.)
Step1: Know Which Changes You’d Like to Make
This is clear: you want to change/edit (or add) a robots.txt file with certain instructions. Be sure to know what those are.
Step 2: Important: Back Up Your robots.txt File (If There is One)
This is simple: just go to your robots.txt file (site.com/robots.txt) and save that file to your computer by clicking Ctrl + S (or whatever the combination is on your keyboard to save a file).
Of course, this is done just in case an error is made.
Step 3: Log in to your WordPress website.
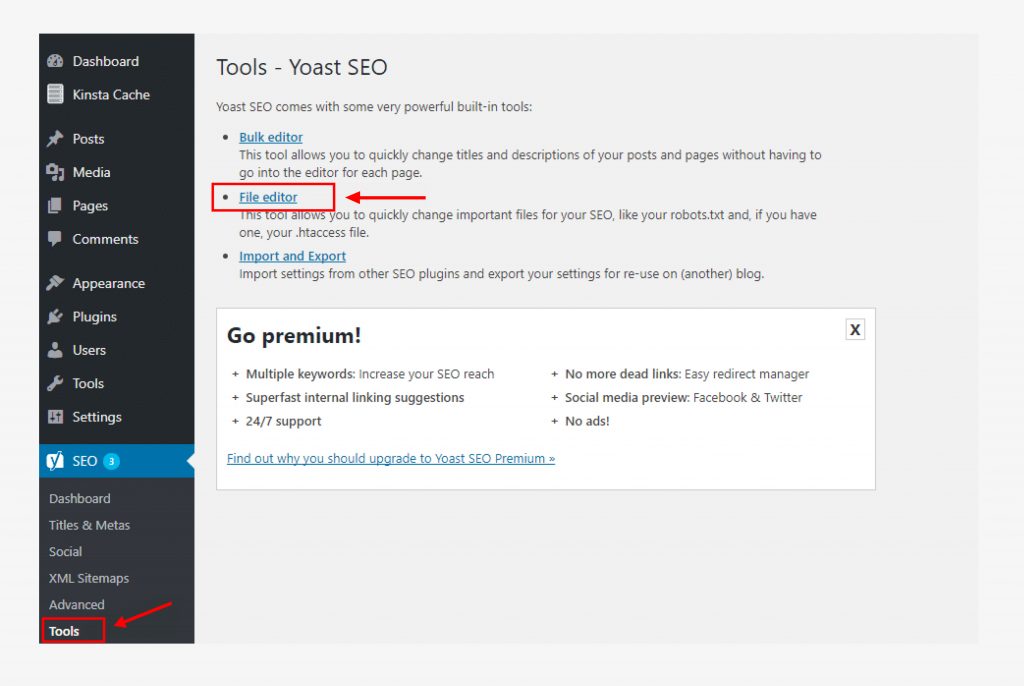
Step 4: Click SEO on the left side of the dashboard. (See the image below.)
Step 5: Click Tools in the SEO settings.
Step 6: Enable the file editing and click on file editor.
This option will not appear if it is disabled.
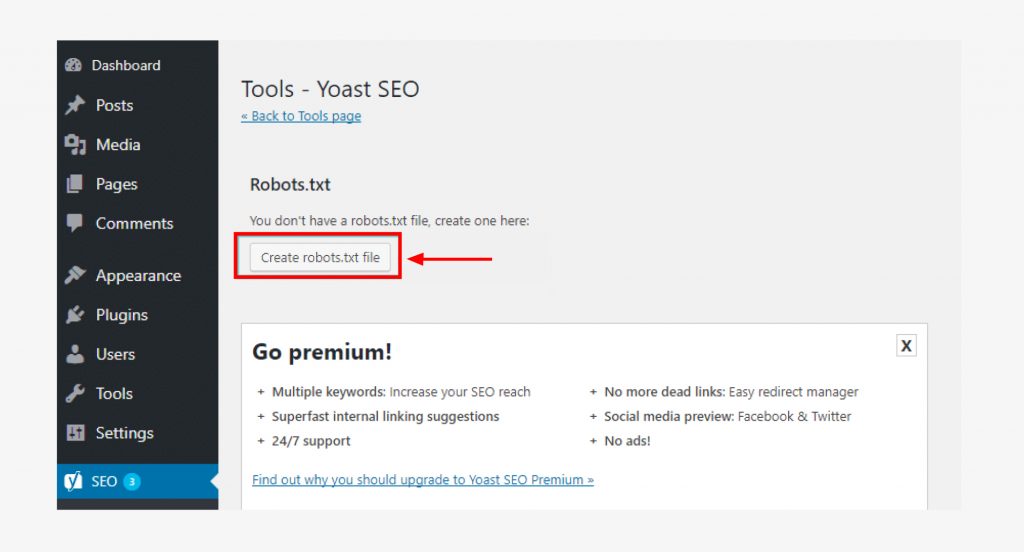
Step 7: Create the changes on your robots.txt file.
You can do this following the examples above, or using any other specific instructions you want to feature.
Step 8: Save these changes.
That should be it! Go to the section below on verifying and testing your robots.txt file.
Remember that when it was installed, WordPress probably created a virtual robots.txt file. Look for this when you go into your site’s folders.
Step 1: Be sure you know which changes you’d like to make, or what you want on your robots.txt file.
Step 2: Important: Make a Backup of Your robots.txt file. Just go to your robots.txt file (site.com/robots.txt) and save that file to your computer. By doing this, if later on, you make an error, you have a previous version to go back to.
Step 3: Using File Transfer Protocol (FTP), cPanel file, or other file management solution, log onto the root of your domain (root folder) and edit (or create) a robots.txt file.
(Alternatively, you can just use a text editor to create a text file on your local computer, put in the instructions you want, save it as robots.txt, and then upload it.)
Save this file with the file name: robots.txt
Step 3: If you created this robots.txt file on your computer, upload it to your domain’s root.
Step 4: Ensure this robots.txt file is there. You can do that by going to yoursite.com/robots.txt
When it comes to coding, there is no room for errors, otherwise, the robots won’t perform the instructions you want.
That’s why you need to validate or check your file.
You can simply do a Google search for a robots.txt validator or checker. There are a number of free options available.
To add instructions to your robots.txt file, just follow the steps above (either via a plugin or FTP).
When you’re all done, do a final test by using a robots.txt validator or checker.
At the beginning of this article, I asked if you felt lost about robots.txt on WordPress sites. Hopefully, things are a bit more clear for you. Remember: robots.txt is just a simple text file that tells search bots (user-agents) where they can and shouldn’t go.
Though robots.txt is probably already on your WordPress installation, you can edit it by using a WordPress plugin (like Yoast SEO) or via your host’s file management system and I hope that though my article, you have a better idea on how to do it on your site.
There are a lot of uses for robots.txt file. While it may not really be a file for seo and does not directly affect rank, it helps in making sure your site and the right pages are crawled, indexed, ranked for your target terms in the search engine results, and gain traffic of search engines. This, in itself, is enough reason to set up your robots.txt file for your WordPress site.
Looking for other was to help you with your search engine optimization strategies and gaining organic traffic to your site? Want to be a SEO expert and looking for more SEO information? Check out our other content on SEO and let us help you get ranked on Google and other major search engines.


Get Our Most 7 Controversial S.I.A. Studies That Will Make Even the Most Advanced SEO Shake Their Head in Disbelief.
Plus we will alert you when we publish new tests to the public.
Obtenga nuestros 7 estudios S.I.A. más controvertidos que harán que incluso el SEO más avanzado sacuda la cabeza con incredulidad.
Además, le avisaremos cuando publiquemos nuevas pruebas al público.
Obtenez nos 7 études S.I.A. les plus controversées qui feront trembler la tête même les SEO les plus avancés d’incrédulité.
De plus, nous vous alerterons lorsque nous publierons de nouveaux tests au public.
Before you can receive free updates, link building strategies or SEO tips you need to confirm your email right now.
(It’s easy)
Just go to your inbox, open the confirmation email from the SIA, and click the link.

And that’s it!
PS: If you don’t see a confirmation email, please check your spam/junk or promotions folders. Sometimes the confirmation message ends up there by mistake.
