
Google has announced that they have launched two improvements to Bard. One of it is Bard’s use of a new technique called Implicit Code Execution which helps the chatbot respond more accurately to mathematical tasks, coding questions, and string manipulations.
This new technique helps Bard detect computational prompts and run code in the background. Bard will get better at answering prompts like:
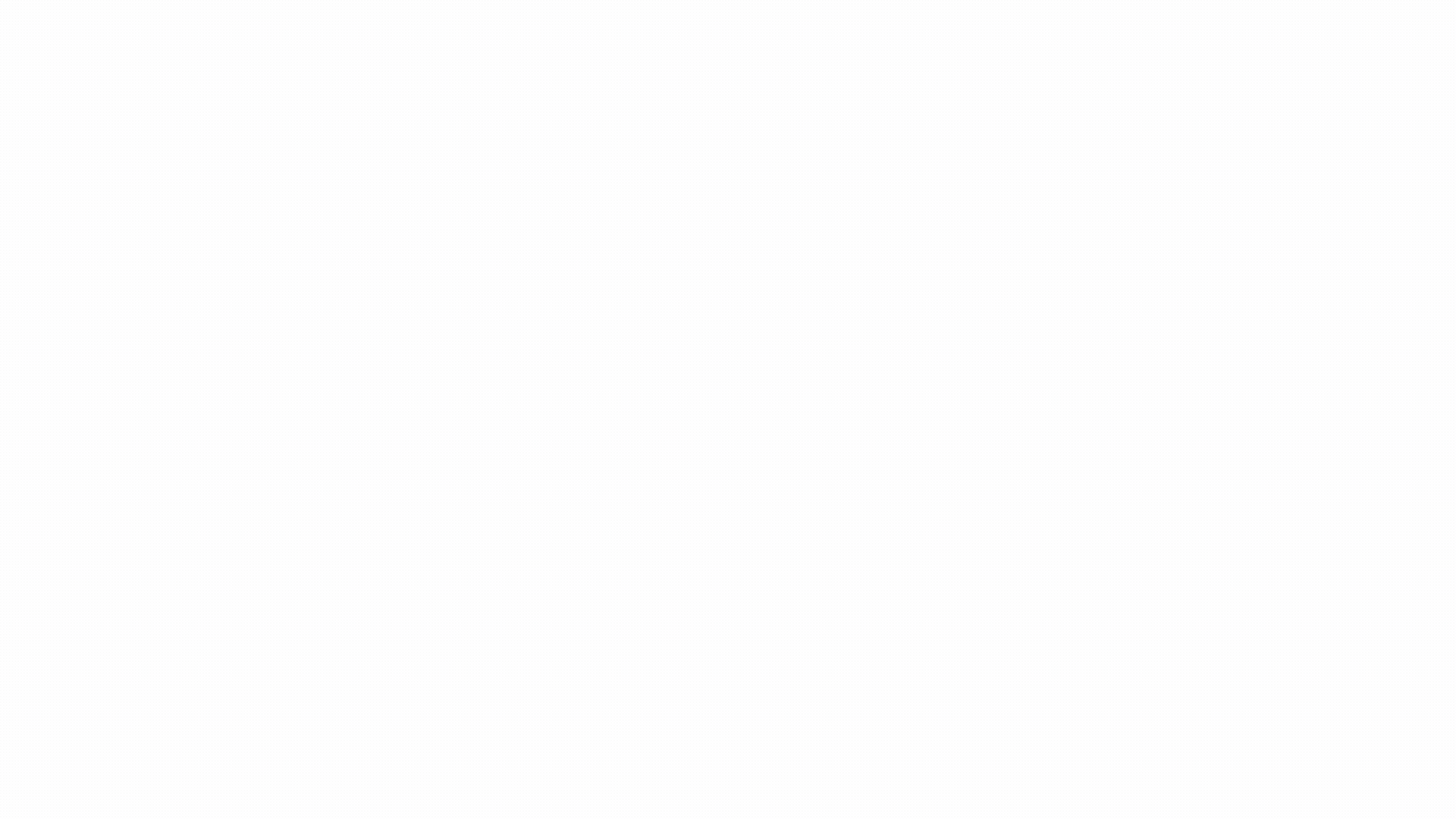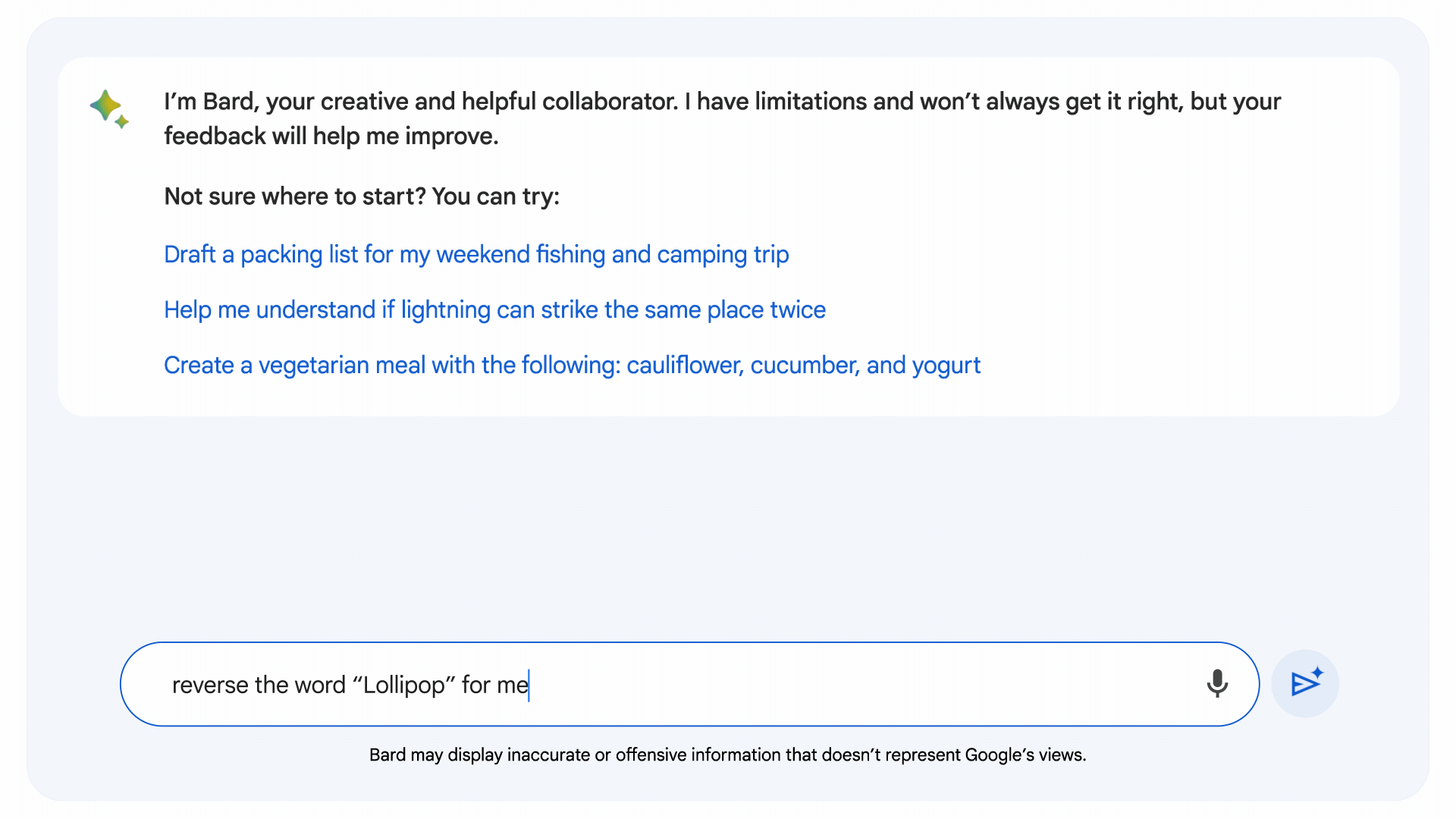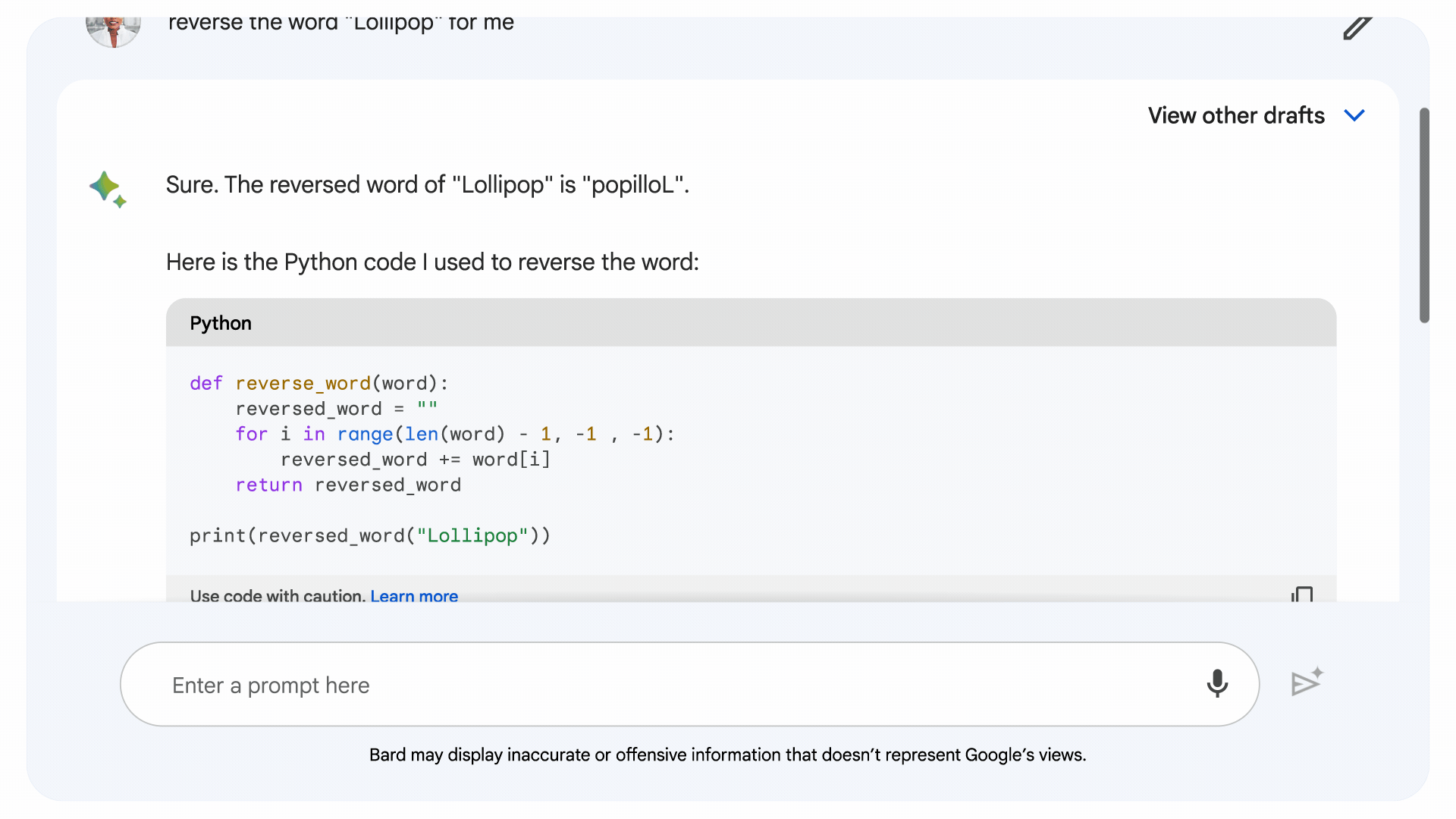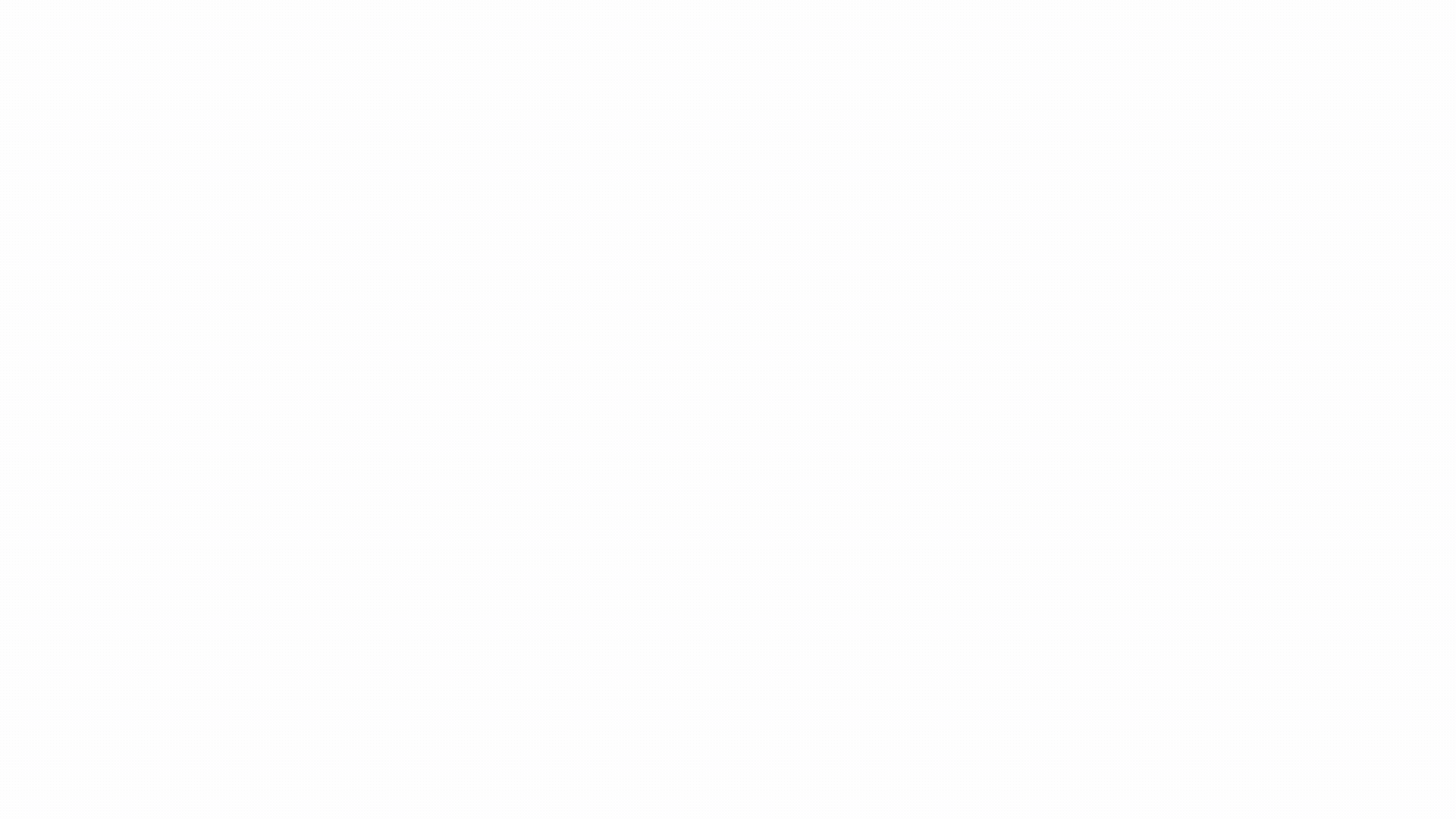
According to Google, Large language models (LLMs) are like prediction engines — when given a prompt, they generate a response by predicting what words are likely to come next. As a result. LLMs have been extremely capable on language and creative tasks, but weaker in areas like reasoning and math. In order to help solve more complex problems with advanced reasoning and logic capabilities, relying solely on LLM output isn’t enough.
This is where the new technique comes in. Implicit code execution allows Bard to generate and execute code to boost its reasoning and math abilities. The approach was inspired by a well-studied dichotomy in human intelligence, notably covered in Daniel Kahneman’s book “Thinking, Fast and Slow” — the separation of “System 1” and “System 2” thinking.
Using this analogy, LLMs can be thought of as operating purely under System 1 — producing text quickly but without deep thought. This leads to some incredible capabilities, but can fall short in some surprising ways. (Imagine trying to solve a math problem using System 1 alone: You can’t stop and do the arithmetic, you just have to spit out the first answer that comes to mind.)
Traditional computation closely aligns with System 2 thinking: It’s formulaic and inflexible, but the right sequence of steps can produce impressive results, such as solutions to long division.
With the latest update, Google has combined the capabilities of both LLMs (System 1) and traditional code (system 2) to help improve Bard’s accuracy. Through implicit code execution, Bard identifies prompts that might benefit from logical code, writes it “under the hood,” executes it and uses the result to generate a more accurate response.
According to Google, they have seen this method improve the accuracy of Bard’s responses to computation-based word and math problems in their internal challenge datasets by approximately 30%.
However, they state that Bard may not always get it right even with these improvements. For example, Bard might not generate code to help the prompt response, the code it generates might be wrong or Bard may not include the executed code in its response. Nevertheless, they will continue to work on improvements to make Bard more helpful and more accurate.
As for the second improvement they have launched, it is a new export action to Google Sheets – when Bard generates a table in its response — like if you ask it to “create a table for volunteer sign-ups for my animal shelter” — you can now export it right to sheets so you could continue working on it further.
Read more about these improvements in this blog post.

Get Our Most 7 Controversial S.I.A. Studies That Will Make Even the Most Advanced SEO Shake Their Head in Disbelief.
Plus we will alert you when we publish new tests to the public.
Obtenga nuestros 7 estudios S.I.A. más controvertidos que harán que incluso el SEO más avanzado sacuda la cabeza con incredulidad.
Además, le avisaremos cuando publiquemos nuevas pruebas al público.
Obtenez nos 7 études S.I.A. les plus controversées qui feront trembler la tête même les SEO les plus avancés d’incrédulité.
De plus, nous vous alerterons lorsque nous publierons de nouveaux tests au public.
Before you can receive free updates, link building strategies or SEO tips you need to confirm your email right now.
(It’s easy)
Just go to your inbox, open the confirmation email from the SIA, and click the link.

And that’s it!
PS: If you don’t see a confirmation email, please check your spam/junk or promotions folders. Sometimes the confirmation message ends up there by mistake.
